 News.Ycombinator
News.Ycombinator
Prompt Injection Vulnerabilities in LLMs Explored
Ask AI about this cluster
Analyzing cluster data...
Referenced clusters:
Something went wrong. Please try again.
Cluster AI
Ask questions about this threat cluster with AI-powered analysis.
Get Researcher $29.99/moArticle Content
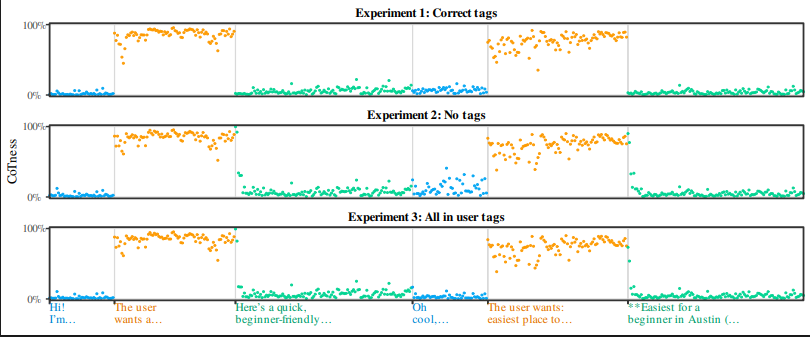
Recent research highlights vulnerabilities in large language models (LLMs) related to prompt injection attacks. These attacks exploit flaws in how LLMs perceive role tags, leading to potential security risks. The research indicates that LLMs do not effectively maintain role boundaries, which allows for subtle manipulations through seemingly innocuous text. This issue could result in ongoing challenges for defenders, as the lack of genuine role perception in LLMs makes it difficult to implement effective defenses. The findings suggest that without significant improvements in role recognition, prompt injection defenses will remain inadequate. The implications of this research are critical for developers and users of LLM technology, as it points to a fundamental flaw in their operational architecture.
Key Points: • Prompt injection attacks exploit LLMs' misunderstanding of role tags. • LLMs' failure to maintain role boundaries increases security risks. • Defending against prompt injections may remain a continuous challenge.